Emoji та юнікод ув динамічному меню
Коли рік тому до імаксу додали інтерактивну хфункцію emoji-insert, я
подумав що hell froze over. Окремий emoji інпут, звичайно, мають всі
ОС багато років. Ув лайнаксі це залежить від середовища стільниці, і
якщо ними (середовищами стільниці) не користуватися, то невблаганну
залізну хватку прогресу можна не помітити.
Нещодавно на хакір н'юз хтось презентував свого менхетнського проекту:
emoji-клавіятуру написану на голому XCB. На що хтось ув
коментарях зазначив
що то є вражаюче досягнення, але маючи список пар
emoji1 опис1
emoji2 опис2
…то emoji вставляються за допомогою будь-якого динамічного меню без спеціяльної клавіятури.
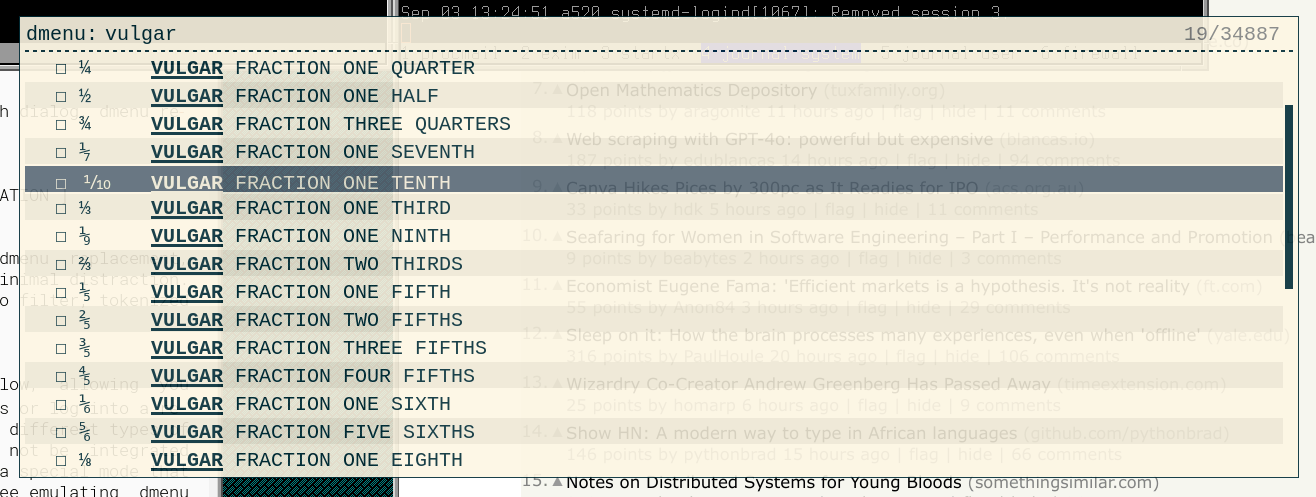
Раніше таким меню була аплікація dmenu (яку я колись ламав для інкрементного аналога alt-tab для FVWM), але зараз гіпадріли користуються rofi, який є ув пекеджах будь-якого дістро:
{kind=link}
$ ls /etc | rofi -dmenu -iОдного rofi буде замало, треба механізма вставки тексту, який друкує rofi на stdout, до активного вікна. Ув xorg це вміє робити xdotool:
$ ls /etc | rofi -dmenu -i | xdotool type --file -Де взяти список пар? Федора має unicode-emoji пекеджа (unicode-data ув
Деб'яні) з файлом emoji-test.txt:

Зліва від середника там список codepoints. Наприклад, щоб отримати чорного кота 🐈⬛, треба взяти звичайного кота (0x1F408, 🐈), додати ZERO WIDTH JOINER (0x200D) та чорного квадрату (0x2B1B, ⬛).
На жаль, %b та \Uxxxx ув printf є непортабельні:
$ e="printf '%b\n' '\U1F408\U200D\U2B1B'"
$ bash -c "$e"
🐈⬛
$ bash -c /bin/"$e"
/bin/printf: missing hexadecimal number in escape
$ dash -c "$e"
\U1F408\U200D\U2B1B
$ busybox sh -c "$e"
\U1F408\U200D\U2B1B
$ zsh -c "$e"
🐈⬛
$ ksh -c "$e"
\U1F408\U200D\U2B1BАле якщо перевести всі hex до int та роздрукувати кожен байт з int ув octal, це буде працювати навіть ув busybox:
$ echo $'\360\237\220\210\342\200\215\342\254\233'
🐈⬛
Файл emoji-test.txt містить 3773 придатних для використання
emojis. Щоб не генерувати статичні пари ув якомусь my-dull-list.txt,
які будуть задавнюватися при кожному оновленні пекеджу, краще написати
швидкого шелóвого фільтра.
Look, ma--no execve() after fork()s:
$ cat codepoint.sh
codepoint_to_oct() {
local dec="`printf %d 0x${1:-0}`"
local b1 b2 b3 b4
if [ "$dec" -lt $((0x80)) ]; then # 1-byte
b1=$dec
elif [ "$dec" -lt $((0x800)) ]; then # 2-byte
b1=$((0xC0 | (dec >> 6)))
b2=$((0x80 | (dec & 0x3F)))
elif [ "$dec" -lt $((0x10000)) ]; then
b1=$((0xE0 | (dec >> 12)))
b2=$((0x80 | ((dec >> 6) & 0x3F)))
b3=$((0x80 | (dec & 0x3F)))
elif [ "$dec" -lt $((0x200000)) ]; then
b1=$((0xF0 | (dec >> 18)))
b2=$((0x80 | ((dec >> 12) & 0x3F)))
b3=$((0x80 | ((dec >> 6) & 0x3F)))
b4=$((0x80 | (dec & 0x3F)))
else
return 1 # out of range
fi
printf \\%03o "$b1" $b2 $b3 $b4
}
emoji_print() { printf %b "`for i; do codepoint_to_oct "$i"; done`"; }Кросиві var assignments ув codepoint_to_oct() написав chatgpt, після
чого Гостре Око помітив що генерувати взагалі потрібно нічого, тому що
emoji-test.txt має для кожного codepint готовий emoji.
$ cat emoji-list.sh
: "${DB:=/usr/share/unicode/emoji/emoji-test.txt}"
grep '; fully-qualified ' "$DB" \
| grep -v 'skin tone' \
| sed -E 's/.+# ([^ ]+) E[^ ]+ (.+)/\1\t\2/'Як відфільтровувати безцінні варіянти з кольором шкіри, список виходить дещо коротший:
$ ./emoji-list.sh | wc -l
1898
$ ./emoji-list.sh | tail -3
🏴 flag: England
🏴 flag: Scotland
🏴 flag: WalesЩоб не викидати codepoint.sh, над яким тяжко пітнів чатбот, можна
зробити додаткового хфінта: друкувати список не лише emojis, а велику
частку utf8:
$ ./unidata-list.sh | grep TELEPHONE
℡ TELEPHONE SIGN
⌕ TELEPHONE RECORDER
☎ BLACK TELEPHONE
☏ WHITE TELEPHONE
✆ TELEPHONE LOCATION SIGN
📞 TELEPHONE RECEIVER
🕻 LEFT HAND TELEPHONE RECEIVER
🕼 TELEPHONE RECEIVER WITH PAGE
🕽 RIGHT HAND TELEPHONE RECEIVER
🕾 WHITE TOUCHTONE TELEPHONE
🕿 BLACK TOUCHTONE TELEPHONE
🖀 TELEPHONE ON TOP OF MODEMДовжина списку таких пар є 34,856. Джерело є текстовий хфайл
UnicodeData.txt з unicode-ucd пекеджу ув Федорі (unicode-data ув
Деб'яні):
$ grep TELEPHONE /usr/share/unicode/ucd/UnicodeData.txt | head -3
2121;TELEPHONE SIGN;So;0;ON;<compat> 0054 0045 004C;;;;N;T E L SYMBOL;;;;
2315;TELEPHONE RECORDER;So;0;ON;;;;;N;;;;;
260E;BLACK TELEPHONE;So;0;ON;;;;;N;;;;;Якщо генерувати списка лінійно, це буде займати кількадесят секунд. Хоча rofi вміє не чекати, а показувати рядки як вони з'являються на його stdin, процес ліпше пришвидшити:
$ cat unidata-list.sh
__dir__=$(dirname "$(readlink -f "$0")")
: "${DB:=/usr/share/unicode/ucd/UnicodeData.txt}"
sed 1,33d "$DB" | while IFS=\; read -r codepoint desc _ _ _ _ _ _ _ _ alt _; do
[ -n "$alt" ] && [ '<' = "`printf %c "$desc"`" ] && desc=$alt
printf '%s %s\n' "$codepoint" "$desc"
done | grep -Eav '^.+\s<' \
| xargs -r -d \\n -n1 -P "`nproc`" "$__dir__/codepoint.sh"до чатботівского codepoint.sh додати:
…
set -e
codepoint=${1%% *}; [ "$codepoint" ]
char=`emoji_print "$codepoint"`; [ "$char" ]
printf '%s\t%s\n' "$char" "${1#[0-9A-F]* }"Якщо навіть з такою кенкаренсі все одно доводиться чекати, споглядаючи цифри прогресу ув rofi, рекомендую користуватися нормальними комп'ютерами, а не raspberry pi.
no subject
BTW, regarding pronouncing "linux": see https://en.wikipedia.org/wiki/Linux.
no subject
у мене лінукс став навіки лайнаксом, коли я ув ~2007 почув це (неіронічно) від hr-тітки (я тоді шукав роботу bsd-сісадміна)
no subject
no subject
фрі, інші варіяції я бачив лише на скріншотах, навіть не знаю навіщо вони потрібні за межами хобі
no subject
no subject
нарід, ви шо, ніколи не чули як linux інколи пренаунсять гамериканці, недотичні до ойті?
no subject
no subject
коли автомеханік каже шо трапилася a blown head gasket, абсолютна більшість немає жодної уяви про шо він балакає, так і, наприклад, цивільна коб'єта чує шо син її подруги "вокс віз комп'ютерс"; одного дня вона читає на msn новину де загадково написано linux і потім ув розмові намагається це слово вимовити
no subject
А нема там чарівного способу отримати лисицю із F та 1F402?
no subject
такого ґліфа (чорна лисиця) немає ув шрифтах, тому буде рендериться лише послідовність з лисиці та квадрату
no subject